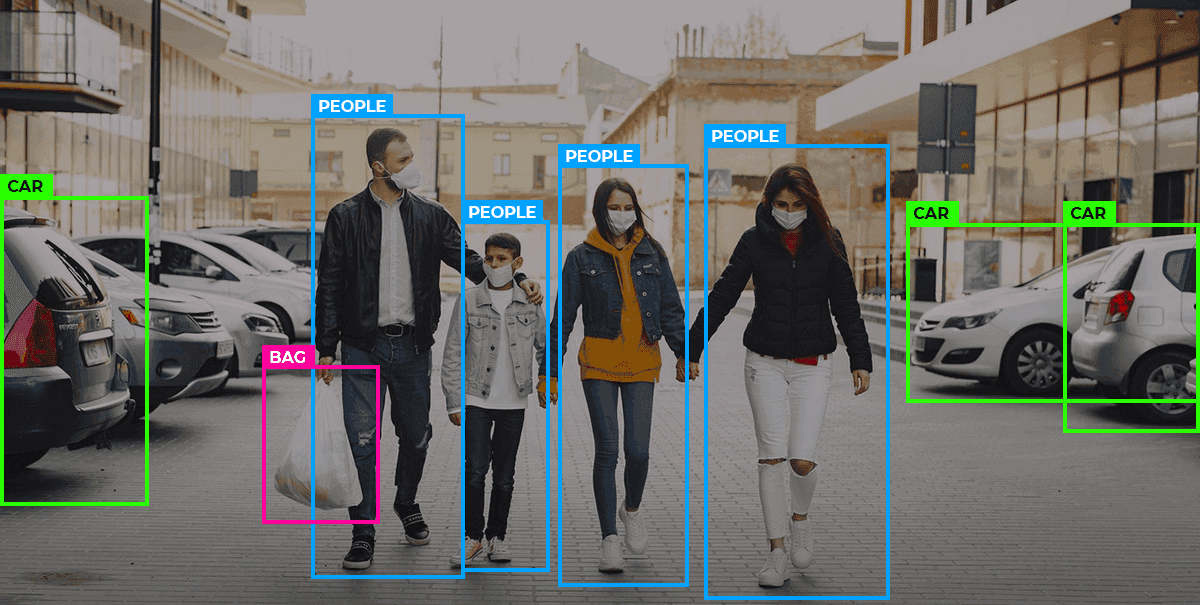
Types of Image Annotation for Machine Learning
Annotating image data is a lot like learning a new language. Imagine placing a sticker on an object with its name written in a foreign language to help you remember it. That’s essentially what image annotation does — it labels parts of an image with tags so that AI systems can understand and recognize what they see.
In this post, we’ll explore what image annotation is, why it’s done, and why it matters more than ever in today’s world — especially if you are:
- A business owner working with large volumes of data,
- An AI or machine learning professional exploring process improvement techniques,
- A beginner in image annotation curious about the different types available,
- An enthusiast fascinated by how AI works,
- Or simply someone interested in the latest tech developments—
This blog will give you a solid understanding of image annotation, its purpose, and why it matters in today’s digital world.
What Is Image Annotation?
Image annotation, also known as labeling or tagging, is the process of adding descriptive metadata to images. This helps machines recognize and understand the objects within those images. In simple terms, it's about marking up images with labels so that AI systems can learn what different objects look like.
For machine learning models to make accurate predictions, they need to be trained on large amounts of annotated data. Image annotation involves identifying and labeling key elements—such as people, animals, vehicles, or buildings—within an image. These labels act as guides, helping the model “see” and learn from the data.
One of the main challenges is that machines don’t perceive images the way humans do. Instead of understanding visual scenes naturally, they process data in binary (ones and zeros). To bridge this gap, annotated images are used to train models—especially those based on neural networks—to detect and distinguish objects through repeated exposure.
Neural networks, which have become increasingly popular in image recognition, are powerful because they can learn from large datasets and improve over time. With enough annotated examples, they become capable of recognizing patterns, making predictions, and even generating labels on new images with minimal human input.
Ultimately, image annotation plays a critical role in machine learning. Without labeled data, AI systems wouldn’t have a foundation to learn from. You can think of labeled data as a training manual—it teaches the model how to detect patterns and make sense of visual information accurately.
Why Perform Image Annotation?
Image annotation is essential because it enables computers to “see” and interpret the contents of images—forming the backbone of Computer Vision (CV), a field of artificial intelligence focused on replicating human visual understanding in machines. In short, CV aims to build systems that can answer image-related questions just like a person would.
To achieve this, machine learning models must be trained using large volumes of annotated data. These labels guide the model in recognizing patterns and making accurate predictions when new, unlabeled images are introduced.
Once a model is trained on well-labeled data, it can tackle real-world problems such as:
- Scanning barcodes and QR codes to track goods and improve logistics processes.
- Recognizing facial features and emotions for security and surveillance systems.
- Detecting roads, vehicles, pedestrians, and obstacles to support self-driving cars in navigating and avoiding collisions.
- Analyzing medical images to identify diseases, abnormalities, or changes in organs.
And these are just a few examples—image annotation powers countless computer vision applications across industries.
It’s important to note that simply collecting vast amounts of raw, unstructured data isn’t enough. Before data can be used to train a model, it must be processed and labeled. Labels tell the model what each element in an image means, allowing it to learn and replicate those identifications.
Labeling images is a form of preprocessing, making objects within them understandable to machine learning systems. Neural networks, one of the most advanced types of machine learning models, rely heavily on annotated data because their learning process closely mirrors human decision-making.
For example, when an AI is trained to detect tumors in medical scans or measure organ structures, the initial labels are created by medical professionals. These human-labeled datasets teach the AI how to analyze and interpret similar scans on its own in the future.
In summary, image annotation is a foundational step in teaching AI to see. Without it, machine learning models would have no reliable examples to learn from—just a sea of meaningless pixels.
The Image Annotation Process
Image annotation is often a manual task, though it can sometimes be assisted by machine learning tools. This has led to the rise of a new profession: data annotators—specialists who label objects in images or verify the accuracy of labels generated by AI systems.
In many cases, annotating certain types of images requires domain-specific knowledge. For example, medical image annotation often demands a background in healthcare or biology to ensure accuracy and reliability.
The image annotation process typically involves the following steps:
Collecting an Unlabeled Dataset
Before labeling begins, a set of raw (unlabeled) images must be assembled. This could include anything from street scenes to satellite imagery to X-ray scans
Defining the Labels
Machine learning or computer vision specialists determine which labels are necessary for the model’s task. Labels could refer to object categories (e.g., cars, people, trees) or more specific attributes (e.g., plant species, facial expressions, road signs).
Annotating the Images
Each image is then manually labeled to highlight the relevant objects. This could involve drawing bounding boxes, creating segmentation masks, or applying classification tags. While many labeled datasets already exist, custom projects often require new labels tailored to specific goals. For instance, annotators might tag various flower species in photos to train a model in plant identification.
Training the Model
Once the images are annotated, the dataset is used to train a computer vision model. The model learns to recognize the patterns and associations between labels and visual data.
Deploying the Model
After training, the model can make predictions on new, unlabeled images—automatically identifying the objects it has learned to recognize.
Steps to Follow When Annotating Data
Regardless of the project type or end goal, the image annotation process typically follows a series of structured steps. Here's how it's generally done:
Data Collection and Preprocessing
Before image annotation can begin, a suitable dataset must be gathered. This involves collecting a large and diverse set of raw images that will serve as training input for a machine learning model. These images may come in the form of digital photos, scanned documents, medical images, or any visual content relevant to the project.
Defining Goals for Image Annotation
Once the required images are collected, the next critical step is to clearly define the goals and objectives of the annotation process. This means determining:
- What needs to be labeled (e.g., objects, features, areas of interest)
- How it should be labeled (e.g., bounding boxes, polygons, key points)
- Why it’s being labeled—what the final outcome should achieve
- What the annotated data will be used for (e.g., training a model for object detection, medical diagnosis, quality inspection)
Having well-defined goals ensures that the annotation work is purpose-driven, consistent, and aligned with the intended machine learning application.
Data Labeling
With goals in place, the next step is labeling the images. Data annotators carefully examine each image, identify relevant objects, and assign labels to them. This adds meaningful context to the raw data, transforming it into a structured format that machines can understand. Labels may include:
- Bounding boxes around objects
- Class names or categories
- Attributes or choices relevant to the task
These annotations become part of the training data, enabling machine learning models to learn from examples. The model studies the labeled data to recognize patterns and make predictions on new, unlabeled images.
Quality Control
The performance of an AI model is directly tied to the accuracy of its annotated training data. If images are labeled incorrectly or inconsistently, the model is likely to produce poor or even harmful results—for example, misidentifying plant species or giving incorrect medical diagnoses. To prevent this, the labeled data must be:
- Accurate – every object must be correctly identified and labeled
- Consistent – the same labeling rules must be applied across the entire dataset
- Reliable – annotations must reflect real-world use cases and expectations
Implementing rigorous quality control measures is essential. These may include:
- Peer reviews or double-checking by senior annotators
- Automated checks to catch obvious errors
- Feedback loops to refine labeling guidelines over time
High-quality, trustworthy annotations are critical to building reliable and safe machine learning systems.
Training and Testing
Once image annotation is complete and quality-checked, the next step is to train the machine learning model using the labeled dataset. During training, the model learns to recognize patterns and relationships between the images and their corresponding labels.
After training, the model is tested on a separate unlabeled dataset to evaluate its performance. This helps determine whether the model can make accurate predictions or classifications on new, unseen data.
Specialists analyze the results to:
- Measure the model's accuracy and reliability
- Identify any weaknesses or biases
- Decide if further data labeling or retraining is needed
While manual annotation is still the foundation of high-quality training data, AI can assist by generating automatic labels for new data. However, automated annotation tools are not yet fully reliable—they still require human oversight to verify and correct their output.
Image Annotation Process: Manual vs. Automated
The most common and straightforward method of image annotation is manual labeling. This approach involves human annotators reviewing raw images and tagging them using specialized annotation tools. While it offers high accuracy, manual annotation is:
- Labor-intensive
- Time-consuming
- Costly
Manual work requires focused attention, precision, and constant quality checks—because even small labeling errors can significantly impact the performance of a machine learning model. The time required to complete annotation depends on several factors:
- Image complexity
- Number of objects per image
- Type of annotation (e.g., bounding boxes, polygons, key points)
- The level of detail required
In some cases, multiple annotators label the same data, and the results are cross-checked or merged for accuracy. While this improves quality, it also increases cost and turnaround time.
Annotators typically follow a clear set of guidelines or checklists to ensure consistency. Using annotation software, they manually:
- Mark object edges
- Apply classification tags
- Draw bounding boxes or polygons
- Annotate facial landmarks or key points
These human-powered methods are especially useful for sensitive or complex projects, such as medical image analysis or autonomous vehicle training.
Data Annotation by Inhouse Specialists
Data annotation performed by in-house specialists is considered one of the most reliable methods for ensuring high-quality and accurate labeled data. This approach allows for full supervision at every stage of the annotation process, which helps maintain strict adherence to guidelines and makes it easier to correct errors in real time. However, this method is also among the most costly and time-consuming, often requiring a large team of employees and dedicated resources. In companies that handle annotation internally, teams may either be pre-trained or require initial training to meet the specific demands of a project. Despite the higher costs, the level of control and precision offered by in-house annotation makes it a preferred choice for projects where data accuracy is critical.
Outsorcing Data Annotation to Third-Parties
Outsourcing data annotation to third-party companies like CloudLytica freelancers is a common alternative to in-house labeling. This approach involves hiring external providers or assembling a remote team of independent annotators, often sourced through freelance marketplaces or professional networks. To ensure efficiency, the company must first establish a structured workflow, define clear responsibilities, and provide detailed guidelines or documentation. In some cases, specialized annotation vendors handle the entire process, including the selection of annotation tools and techniques, which they may not fully disclose to the client. The overall quality of the annotated data in this model largely depends on the reliability, experience, and accountability of the outsourced team or service provider.
Annotation Process Automation
Automation in image annotation is designed to simplify and reduce the cost of manual labeling work. It involves the use of artificial intelligence (AI) to assist in tagging, enhancing, or labeling datasets. With this capability, annotation tools can accelerate the process and support human annotators, significantly reducing the time and resources needed for preparing data for machine learning. However, while automation can improve efficiency and lower costs, human involvement remains crucial to maintain accuracy and consistency. Human operators are responsible for monitoring, correcting, and refining automated outputs. Since automated labeling is still not flawless, human oversight is essential to catch and fix errors, ensuring the overall quality of the annotated data remains high.
Crowdsourcing
Crowdsourcing allows image annotation tasks to be distributed among hundreds or even thousands of contributors, with each individual handling a small portion of the dataset. Participants on crowdsourcing platforms select and complete various micro-tasks, which are often reviewed and verified by other contributors—sometimes working in small teams—before the results are aggregated into a final labeled dataset. This method is typically the most cost-effective and easiest to scale, making it ideal for large-volume projects. However, its main drawback is the potential for reduced labeling accuracy. To ensure quality, it’s essential to have clearly defined objectives, effective communication, robust quality control measures, and a well-organized annotation workflow in place.
Types of Image Annotation
Image annotation projects are carried out using a range of techniques and workflows, depending on the goals and complexity of the task. To begin the annotation process, a dedicated image annotation tool is essential. This tool should come equipped with the necessary features and functionalities to support accurate and efficient labeling, tailored to the specific needs of each project. Since image annotations can take many different forms, it’s important to choose the appropriate method based on the use case. Below are some of the most common types of image annotations.
Cuboid or 3D Bounding Box Annotation
Cuboid annotation, also known as 3D bounding box annotation, is the three-dimensional extension of the 2D bounding box technique. While both methods involve enclosing objects with rectangles, cuboids provide an added layer of depth, making it possible to represent the object’s size and position in a 3D space. This is especially valuable in projects where understanding an object’s dimensions, volume, and spatial orientation is crucial—such as in autonomous driving, robotics, or augmented reality applications.
To create a cuboid, annotators place anchor points on the object's edges to capture length, width, and depth, effectively building a box that simulates a 3D outline around the object. However, challenges arise when objects are partially obscured or not fully visible, making it difficult or even impossible to draw an accurate 3D box. In such cases, additional validation or alternative annotation methods may be required.
2D Bounding Box Image Annotation
2D bounding boxes are one of the most commonly used image annotation techniques. They involve drawing rectangular frames around objects to mark their position within an image. This method is particularly well-suited for symmetrical or regularly shaped objects. By enclosing an object in a box and assigning relevant details, annotators help machine learning models learn to detect and locate objects within frames.
This technique is widely used in applications such as object detection, counting, and tracking, especially in fields like surveillance, where systems need to recognize and count individuals in video footage.
To annotate with 2D bounding boxes, annotators manually draw rectangles around each object of interest. In some cases, all objects belong to the same category. In others, multiple object classes are present, and the annotator must select the correct label from a predefined list after placing each box.
Annotation by Use of Lines and Splines
In some cases, using plain lines or splines is an effective way to annotate elements within an image. This technique is especially useful in applications involving self-driving cars, drones, warehouse robots, and similar technologies. Annotators use lines and curves to mark features such as road lanes, pathways, sidewalks, electrical lines, and other boundaries or directional guides.
Line and spline annotations are commonly used to help systems recognize traffic lanes, edges, tracks, and to map out navigational paths. These annotations enable autonomous vehicles and aerial systems to better understand their environment by defining limits and safe zones. As a result, they play a key role in teaching machines how to make more accurate and informed decisions in real-world driving, flying, or navigation scenarios.
Skeletal or Key Point Image Annotation
Skeletal or key point annotation is ideal for capturing detailed movements and positions of objects, particularly in images or video footage involving motion. This method is commonly used for facial recognition, where annotators mark key facial features to identify expressions, gestures, and head poses. It's also widely used in pose estimation, where points are applied to track body joints and limb positions.
During annotation, the specialist must label each key point according to the task’s logic—for example, marking the corners of the eyes, elbows, knees, or fingertips. In some cases, different colors are assigned to key points representing different object classes or body parts. This helps the model more accurately interpret and track the spatial relationships and movements of the various components, which is crucial in fields like human activity recognition, sports analytics, and virtual try-on technologies.
Image Classification
Unlike bounding boxes, which focus on labeling multiple individual items within an image, image classification involves assigning a single label to the entire image. This type of annotation aims to identify the main subject or theme of an image, rather than highlighting specific objects or regions within it. It’s commonly used to detect the presence of similar content across large datasets.
Image classification operates at a high level of abstraction, without breaking the image down into its finer details. For example, a photo of a garden containing flowers, trees, and grass might simply be labeled as "nature" instead of tagging each element individually as "flower," "bush," or "grass."
Annotators use this method to train machine learning models to recognize similar patterns in new, unlabeled images based on previously labeled examples. It’s especially useful in tasks like content categorization, spam detection, and large-scale image sorting.
Semantic Image Segmentation
Semantic segmentation involves annotating images at the pixel level, assigning a specific class label to every pixel in the image. Unlike other annotation methods that focus on bounding or identifying entire objects, this approach divides the image into precise segments, where each region corresponds to a particular object or class.
Rather than selecting individual items from a list, annotators are provided with segment labels and are tasked with carefully outlining the boundaries of each object. This results in pixel-perfect annotations that allow machine learning models to better understand how different objects and regions interact within an image.
The output typically appears as color-coded masks, where each color represents a distinct object class. Semantic segmentation is especially valuable when it’s critical to not only locate objects within a frame but also to define their exact shape and coverage—such as in medical imaging, autonomous driving, and scene understanding.
Side-by-Side Comparison
Side-by-side comparison is a form of image annotation where annotators are shown two images and asked to select the one that is more suitable or relevant to a specific task or objective. This method is commonly used in projects that involve user preference evaluation, such as determining which interface layout is more appealing or which image is more effective for advertising or content targeting.
This approach allows machine learning models to learn from human judgments, helping them rank or recommend content based on subtle visual differences or contextual suitability.
While image annotation comes in many forms, side-by-side comparison is one of the key techniques currently in use—particularly in applications where subjective evaluation or user intent is critical to success.
Polygonal Image Segmentation
Objects in real-world images are often irregular and not perfectly symmetrical, making simple shapes like rectangles inadequate for precise annotation. Polygonal image segmentation allows annotators to accurately capture the true shape of such objects. Using this method, annotators place dots along the edges of the object and manually trace lines around its perimeter, adjusting direction as needed to closely follow the object's contours.
Once the shape is fully outlined, the object is labeled with a tag that describes its class or attributes. This technique is especially effective for objects with complex or non-rectangular shapes, such as animals, tools, road signs, or organic forms like trees and plants.
Because polygons can define more angles and intricate edges than bounding boxes, they offer a more detailed and realistic representation of the object. This makes polygonal segmentation a preferred method in scenarios that demand high precision, such as autonomous driving, medical imaging, and aerial surveillance.
Conclusion
Artificial Intelligence has become an integral part of our daily lives, and the future development of virtually every industry will depend on the continued adoption of AI technologies. At the core of this progress lies image annotation—a foundational step in building intelligent systems, particularly in the field of computer vision.
Through large datasets of labeled images, machine learning models learn to recognize and interpret visual information on their own, mimicking the way humans perceive and understand the world. This process is essential for training models to detect, classify, and respond to visual data accurately. There are various image annotation techniques, each tailored to specific objectives. For example:
- 2D bounding boxes are ideal for marking simple, symmetrical objects and counting items within an image.
- Cuboids (3D bounding boxes) add depth and are used when spatial orientation and volume are important.
- Key point annotation is suited for tracking facial expressions, body poses, or fine-grained object movements.
The type of annotation you choose should align with your project’s goals and the level of precision required. Whether you're building autonomous vehicles, facial recognition systems, or medical diagnostic tools, selecting the right annotation method is crucial to creating effective and reliable AI solutions. Ultimately, the development of cutting-edge computer vision technologies is only possible through accurate, purpose-driven image annotation.